![]()
![]()
![]()
The recent popularity of the MBONE has led to the deployment of multicast applications such as video-conferencing, distributed interactive simulation, and news distribution. Many of these applications require reliable data delivery, which is not provided by IP Multicast, necessitating higher level protocols that work on top of the network multicast service. Large scale applications (e.g., DIS) complicate the problem because of the large numbers of participants distributed over a wide geographical area, and the highly dynamic nature of their topology and population. These applications pose challenges that traditional error control schemes such as TCP cannot handle efficiently.
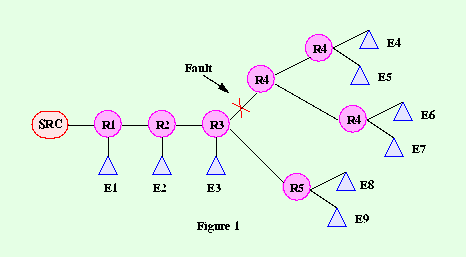
The challenges currently faced by reliable multicast within the context of IP Multicast include the following (depicted with the aid of Fig. 1):
Currently, the most popular solutions to these problems are based on one of two approaches: (a) schemes employing randomized back-off timers, and (b) schemes employing a tree hierarchy. In the former, the general mechanism is as follows: when a loss is detected, each member starts a random timer before sending a request. The member which selected the shortest timer sends a request, which cancels all other requests. The reception of the request starts back-off timers among all the members which have the reply. A reply will be sent by the member with the shortest timer, which will cancel all other replies.
Randomized back-off schemes offer a tradeoff between implosion and latency: the longer the timeout interval the lower the implosion, but at the expense of higher latency. With large multicast groups, the latency penalty can be quite high. In addition, these schemes have no inherent ability to perform local recovery (to reduce exposure). Instead, they rely on limiting the scope of recovery messages using the TTL value in the IP header. However, this is a crude method of limiting exposure, as it limits messages to a radius, not a subtree. On the plus side, these schemes are very robust: a loss will be recovered even if only one member of the group has the requested data (but at the expense of exposure).
Schemes employing a tree hierarchy arrange group members into a tree. Requests are restricted to travel from children to their parents, and replies from parents to children. Thus requests and replies cannot propagate to the whole group, restricting implosion and eliminating exposure. However, for best results the tree hierarchy must follow the topology of the multicast tree created by the routing protocol. This is hard to do without access to routing information, thus some employ a static tree structure. In addition, whenever the group structure changes, as for example when members join or leave, the tree needs to be restructured, which is an expensive operation.
Thus, currently proposed solutions offer different tradeoffs: randomized back-off schemes offer good robustness, but trade latency for reducing implosion and rely on crude methods to limit exposure. Tree-based schemes offer good implosion control, low latency and low exposure; but tree formation is a problem, and do not adapt well to dynamic membership changes because they either use a static tree structure, or use complex operations to form a dynamic tree.
This leads to two additional challenges faced by reliable multicast:
In this project, we address all the above 5 problems by following a different approach: we modify the IP Multicast service model to allow routers to offer a small set of new forwarding services to the members of a multicast group. Applications develop error control schemes that can leverage off these new services to provide reliability. The services do not impose a specific error control scheme. The implementation of these services at the routers eliminates the need for endpoints to learn about group topology. Additionally, it allows easy access to topology information, which leads to an efficient implementation. These forwarding services are conceptually simple, and while they do require some changes at the routers, they do not violate the end-to-end argument, and merge well with current IP routing and group management protocols.
![]()
Research Plan ![]() Solution Overview
Solution Overview ![]() Infocom Paper
Infocom Paper ![]() Presentation
Presentation ![]() People
People ![]() ARL
ARL
![]()